پیش از این، CMS یک روش حذف پرت Tukey را هنگام محاسبه امتیاز ستاره Medicare Advantage (MA) و Medicare Part D Plans Drug Prescription Drug (PDP) اجرا کرد. با این حال، یک قانون نهایی که در سال 2022 اجرا شد، استفاده از حذف پرت Tukey را از معیارهای کیفیت حذف کرد. بر اساس دادههای تاریخی 2020، 17 درصد از طرحهای MA رتبهبندی ستارههای پایینتری دارند در حالی که تنها 1 درصد پس از حذف حذف توکی، رتبهبندی ستارههای بالاتری خواهند داشت. این سوال پیش می آید که Tukey Outlier چیست.
تعاریف Outlier Tukey.
نقاط پرت Tukey نقاط داده ای هستند که خارج از محدوده زیر قرار دارند.
- {Q1 – k(IQR)، Q3+k(IQR)}
در اینجا Q1 و Q3 به ترتیب ربع های اول و سوم داده ها هستند و IQR محدوده بین ربع است (یعنی تفاوت بین ربع سوم و اول). عبارت ک یک ضریب است که نشان می دهد چقدر می خواهید نسبت به موارد پرت حساس باشید. جان توکی این را پیشنهاد کرد ک = 1.5 نشاندهنده یک “غیرطبیعی” است، و ک = 3 داده هایی را نشان می دهد که “خیلی دور” هستند.
چقدر احتمال دارد که با روش Tukey یک نقطه پرت را شناسایی کنید؟
پاسخ به این سوال به (i) اینکه محدوده Tukey شما چقدر گسترده است (یعنی مقدار). ک) و (ii) شکل توزیع شما. Andrey Akinshin برای پاسخ به این سوال برای توزیع های Normal، Gumbel و نمایی شبیه سازی هایی ایجاد کرد. نتایج در زیر آمده است. همانطور که در زیر می بینید، توزیع های غیر نرمال – به ویژه نمایی – به احتمال زیاد با استفاده از روش توکی، یک حالت پرت مشاهده می شود.
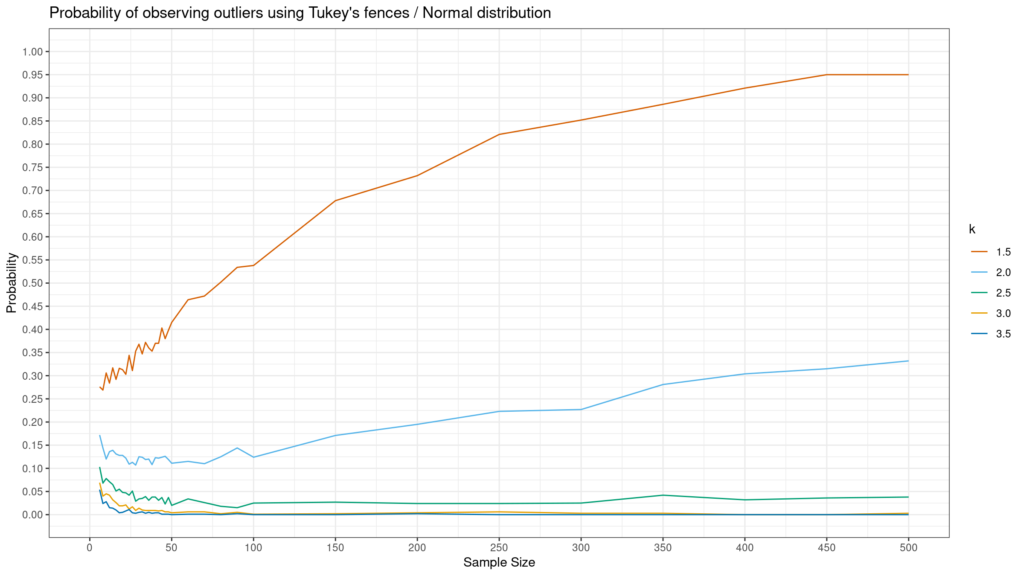
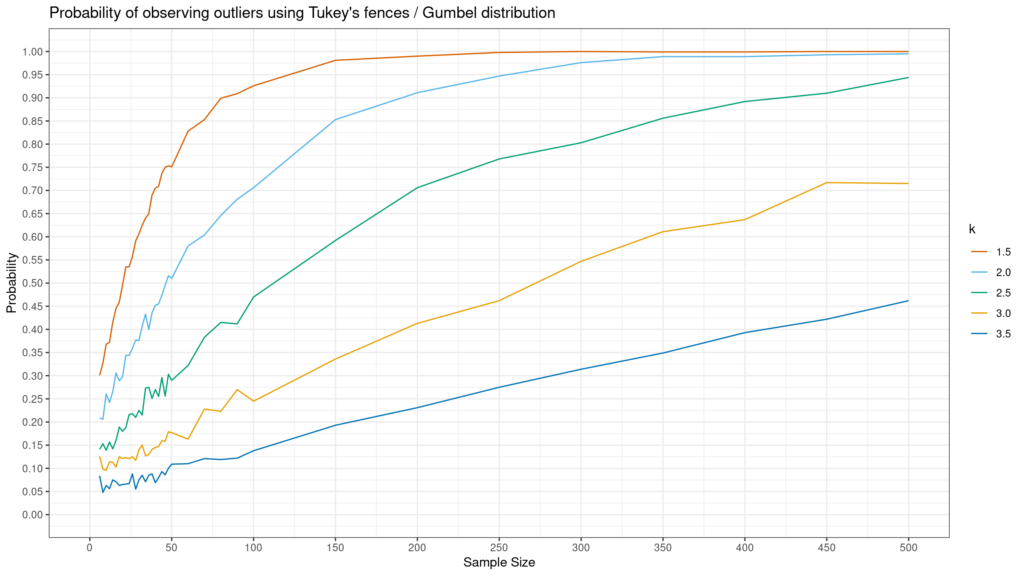
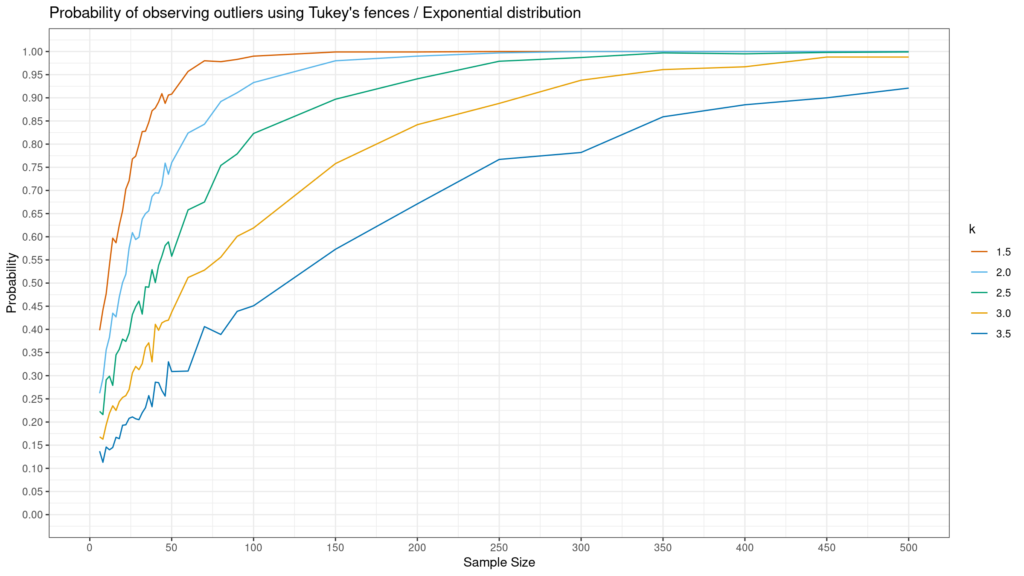
مانند همه موارد پرت، شناسایی کلیدی است اما اینکه با آنها چه باید کرد بستگی به زمینه دارد. اگر اینها خطاهای داده یا موقعیتهای غیرعادی خالص هستند، ممکن است بخواهید آنها را حذف کنید. از سوی دیگر، اگر اینها فقط مقادیر پرت هستند که گهگاه اتفاق میافتند، باید آنها را در دادهها رها کرد و فقط سعی کرد بهتر بفهمد که آیا فرآیند تولید دادهای وجود دارد که با فرآیند معمولی که میتواند این موارد را ایجاد کند متفاوت است یا خیر. ارزش های. در هر صورت، روش Tukey یک روش مفید و ساده برای شناسایی موارد پرت است، اما به شما نمی گوید که پس از شناسایی با آنها چه کنید.